 By
By Graph Neural Networks
Contents
8. Graph Neural Networks#
Historically, the biggest difficulty for machine learning with molecules was the choice and computation of “descriptors”. Graph neural networks (GNNs) are a category of deep neural networks whose inputs are graphs and provide a way around the choice of descriptors. A GNN can take a molecule directly as input.
Audience & Objectives
This chapter builds on Standard Layers and Regression & Model Assessment. Although it is defined here, it would be good to be familiarize yourself with graphs/networks. After completing this chapter, you should be able to
Represent a molecule in a graph
Discuss and categorize common graph neural network architectures
Build a GNN and choose a read-out function for the type of labels
Distinguish between graph, edge, and node features
Formulate a GNN into edge-updates, node-updates, and aggregation steps
GNNs are specific layers that input a graph and output a graph. You can find reviews of GNNs in Dwivedi et al.[DJL+20], Bronstein et al.[BBL+17], and Wu et al.[WPC+20]. GNNs can be used for everything from coarse-grained molecular dynamics [LWC+20] to predicting NMR chemical shifts [YCW20] to modeling dynamics of solids [XFLW+19]. Before we dive too deep into them, we must first understand how a graph is represented in a computer and how molecules are converted into graphs.
You can find an interactive introductory article on graphs and graph neural networks at distill.pub [SLRPW21]. Most current research in GNNs is done with specialized deep learning libraries for graphs. As of 2022, the most common are PyTorch Geometric, Deep Graph library, DIG, Spektral, and TensorFlow GNNS.
8.1. Representing a Graph#
A graph \(\mathbf{G}\) is a set of nodes \(\mathbf{V}\) and edges \(\mathbf{E}\). In our setting, node \(i\) is defined by a vector \(\vec{v}_i\), so that the set of nodes can be written as a rank 2 tensor. The edges can be represented as an adjacency matrix \(\mathbf{E}\), where if \(e_{ij} = 1\) then nodes \(i\) and \(j\) are connected by an edge. In many fields, graphs are often immediately simplified to be directed and acyclic, which simplifies things. Molecules are instead undirected and have cycles (rings). Thus, our adjacency matrices are always symmetric \(e_{ij} = e_{ji}\) because there is no concept of direction in chemical bonds. Often our edges themselves have features, so that \(e_{ij}\) is itself a vector. Then the adjacency matrix becomes a rank 3 tensor. Examples of edge features might be covalent bond order or distance between two nodes.
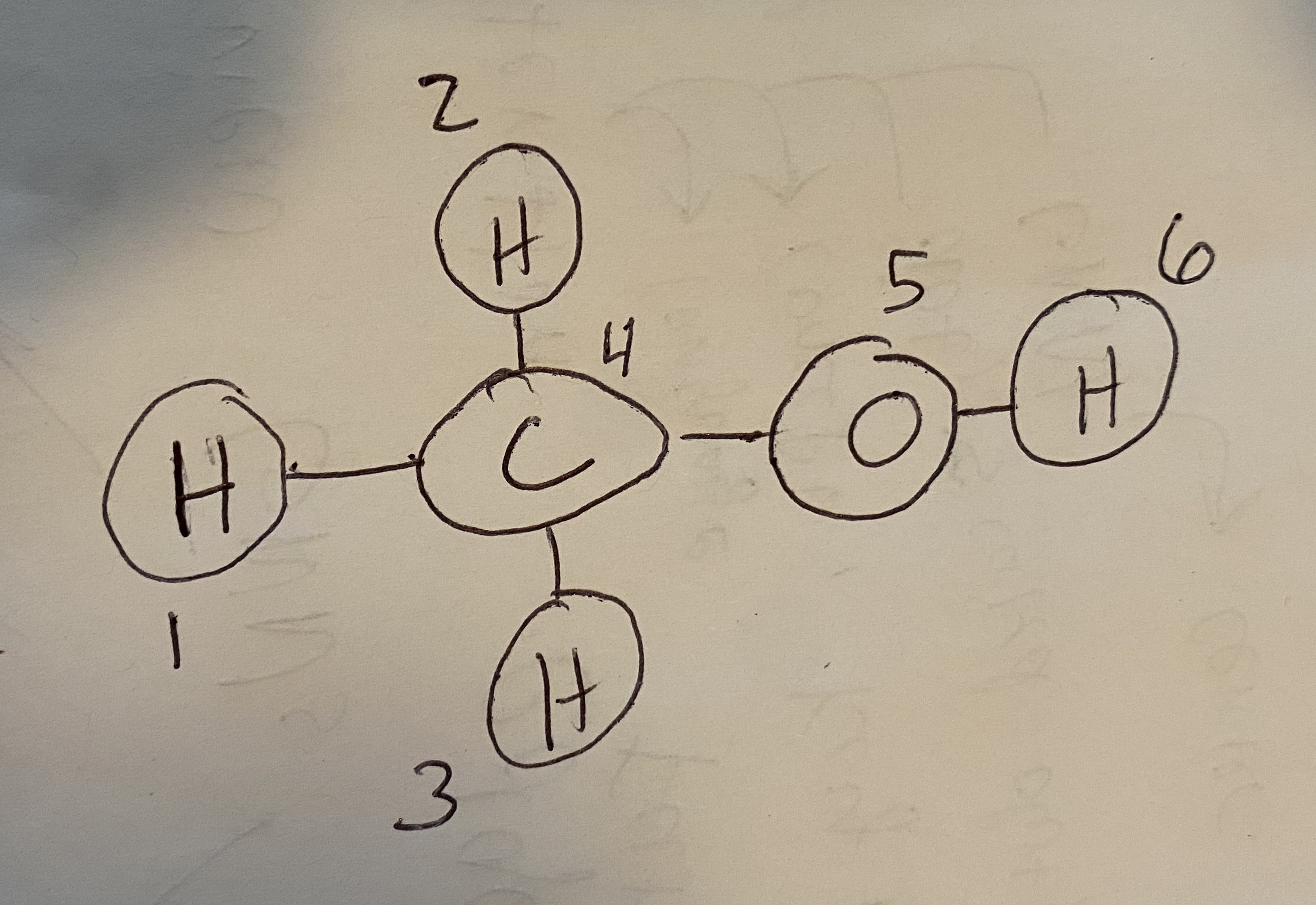
Fig. 8.1 Methanol with atoms numbered so that we can convert it to a graph.#
Let’s see how a graph can be constructed from a molecule. Consider methanol, shown in Fig. 8.1. I’ve numbered the atoms so that we have an order for defining the nodes/edges. First, the node features. You can use anything for node features, but often we’ll begin with one-hot encoded feature vectors:
Node |
C |
H |
O |
|---|---|---|---|
1 |
0 |
1 |
0 |
2 |
0 |
1 |
0 |
3 |
0 |
1 |
0 |
4 |
1 |
0 |
0 |
5 |
0 |
0 |
1 |
6 |
0 |
1 |
0 |
\(\mathbf{V}\) will be the combined feature vectors of these nodes. The adjacency matrix \(\mathbf{E}\) will look like:
1 |
2 |
3 |
4 |
5 |
6 |
|
|---|---|---|---|---|---|---|
1 |
0 |
0 |
0 |
1 |
0 |
0 |
2 |
0 |
0 |
0 |
1 |
0 |
0 |
3 |
0 |
0 |
0 |
1 |
0 |
0 |
4 |
1 |
1 |
1 |
0 |
1 |
0 |
5 |
0 |
0 |
0 |
1 |
0 |
1 |
6 |
0 |
0 |
0 |
0 |
1 |
0 |
Take a moment to understand these two. For example, notice that rows 1, 2, and 3 only have the 4th column as non-zero. That’s because atoms 1-3 are bonded only to carbon (atom 4). Also, the diagonal is always 0 because atoms cannot be bonded with themselves.
You can find a similar process for converting crystals into graphs in Xie et al. [XG18]. We’ll now begin with a function which can convert a smiles string into this representation.
8.2. Running This Notebook#
Click the above to launch this page as an interactive Google Colab. See details below on installing packages.
Tip
To install packages, execute this code in a new cell.
!pip install dmol-book
If you find install problems, you can get the latest working versions of packages used in this book here
import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import tensorflow as tf
import pandas as pd
import rdkit, rdkit.Chem, rdkit.Chem.rdDepictor, rdkit.Chem.Draw
import networkx as nx
import dmol
soldata = pd.read_csv(
"https://github.com/whitead/dmol-book/raw/main/data/curated-solubility-dataset.csv"
)
np.random.seed(0)
my_elements = {6: "C", 8: "O", 1: "H"}
The hidden cell below defines our function smiles2graph. This creates one-hot node feature vectors for the element C, H, and O. It also creates an adjacency tensor with one-hot bond order being the feature vector.
def smiles2graph(sml):
"""Argument for the RD2NX function should be a valid SMILES sequence
returns: the graph
"""
m = rdkit.Chem.MolFromSmiles(sml)
m = rdkit.Chem.AddHs(m)
order_string = {
rdkit.Chem.rdchem.BondType.SINGLE: 1,
rdkit.Chem.rdchem.BondType.DOUBLE: 2,
rdkit.Chem.rdchem.BondType.TRIPLE: 3,
rdkit.Chem.rdchem.BondType.AROMATIC: 4,
}
N = len(list(m.GetAtoms()))
nodes = np.zeros((N, len(my_elements)))
lookup = list(my_elements.keys())
for i in m.GetAtoms():
nodes[i.GetIdx(), lookup.index(i.GetAtomicNum())] = 1
adj = np.zeros((N, N, 5))
for j in m.GetBonds():
u = min(j.GetBeginAtomIdx(), j.GetEndAtomIdx())
v = max(j.GetBeginAtomIdx(), j.GetEndAtomIdx())
order = j.GetBondType()
if order in order_string:
order = order_string[order]
else:
raise Warning("Ignoring bond order" + order)
adj[u, v, order] = 1
adj[v, u, order] = 1
return nodes, adj
nodes, adj = smiles2graph("CO")
nodes
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 0., 1.],
[0., 0., 1.],
[0., 0., 1.]])
8.3. A Graph Neural Network#
A graph neural network (GNN) is a neural network with two defining attributes:
Its input is a graph
Its output is permutation equivariant
We can understand clearly the first point. Here, a graph permutation means re-ordering our nodes. In our methanol example above, we could have easily made the carbon be atom 1 instead of atom 4. Our new adjacency matrix would then be:
1 |
2 |
3 |
4 |
5 |
6 |
|
|---|---|---|---|---|---|---|
1 |
0 |
1 |
1 |
1 |
1 |
0 |
2 |
1 |
0 |
0 |
0 |
0 |
0 |
3 |
1 |
0 |
0 |
0 |
0 |
0 |
4 |
1 |
0 |
0 |
0 |
1 |
0 |
5 |
1 |
0 |
0 |
0 |
0 |
1 |
6 |
0 |
0 |
0 |
0 |
1 |
0 |
A GNN is permutation equivariant if the output change the same way as these exchanges. If you are trying to model a per-atom quantity like partial charge or chemical shift, this is obviously essential. If you change the order of atoms input, you would expect the order of their partial charges to similarly change.
Often we want to model a whole-molecule property, like solubility or energy. This should be invariant to changing the order of the atoms. To make an equivariant model invariant, we use read-outs (defined below). See Input Data & Equivariances for a more detailed discussion of equivariance.
8.3.1. A simple GNN#
We will often mention a GNN when we really mean a layer from a GNN. Most GNNs implement a specific layer that can deal with graphs, and so usually we are only concerned with this layer. Let’s see an example of a simple layer for a GNN:
This equation shows that we first multiply every node (\(v_{ij}\)) feature by trainable weights \(w_{jk}\), sum over all node features, and then apply an activation. This will yield a single feature vector for the graph. Is this equation permutation invariant? Yes, because the node index in our expression is index \(i\) which can be re-ordered without affecting the output.
Let’s see an example that is similar, but not permutation invariant:
This is a small change. We have one weight vector per node now. This makes the trainable weights depend on the ordering of the nodes. Then if we swap the node ordering, our weights will no longer align. So if we were to input two methanol molecules, which should have the same output, but we switched two atom numbers, we would get different answers. These simple examples differ from real GNNs in two important ways: (i) they give a single feature vector output, which throws away per-node information, and (ii) they do not use the adjacency matrix. Let’s see a real GNN that has these properties while maintaining permutation invariance — or equivariance (swapping inputs swaps outputs the same way).
8.4. Kipf & Welling GCN#
One of the first popular GNNs was the Kipf & Welling graph convolutional network (GCN) [KW16]. Although some people consider GCNs to be a broad class of GNNs, we’ll use GCNs to refer specifically the Kipf & Welling GCN. Thomas Kipf has written an excellent article introducing the GCN.
The input to a GCN layer is \(\mathbf{V}\), \(\mathbf{E}\) and it outputs an updated \(\mathbf{V}'\). Each node feature vector is updated. The way it updates a node feature vector is by averaging the feature vectors of its neighbors, as determined by \(\mathbf{E}\). The choice of averaging over neighbors is what makes a GCN layer permutation equivariant. Averaging over neighbors is not trainable, so we must add trainable parameters. We multiply the neighbor features by a trainable matrix before the averaging, which gives the GCN the ability to learn. In Einstein notation, this process is:
where \(i\) is the node we’re considering, \(j\) is the neighbor index, \(k\) is the node input feature, \(l\) is the output node feature, \(d_i\) is the degree of node i (which makes it an average instead of sum), \(e_{ij}\) isolates neighbors so that all non-neighbor \(v_{jk}\)s are zero, \(\sigma\) is our activation, and \(w_{lk}\) is the trainable weights. This equation is a mouthful, but it truly just is the average over neighbors with a trainable matrix thrown in. One common modification is to make all nodes neighbors of themselves. This is so that the output node features \(v_{il}\) depends on the input features \(v_{ik}\). We do not need to change our equation, just make the adjacency matrix have \(1\)s on the diagonal instead of \(0\) by adding the identity matrix during pre-processing.
Building understanding about the GCN is important for understanding other GNNs. You can view the GCN layer as a way to “communicate” between a node and its neighbors. The output for node \(i\) will depend only on its immediate neighbors. For chemistry, this is not satisfactory. You can stack multiple layers though. If you have two layers, the output for node \(i\) will include information about node \(i\)’s neighbors’ neighbors. Another important detail to understand in GCNs is that the averaging procedure accomplishes two goals: (i) it gives permutation equivariance by removing the effect of neighbor order and (ii) it prevents a change in magnitude in node features. A sum would accomplish (i) but would cause the magnitude of the node features to grow after each layer. Of course, you could ad-hoc put a batch normalization layer after each GCN layer to keep output magnitudes stable but averaging is easy.
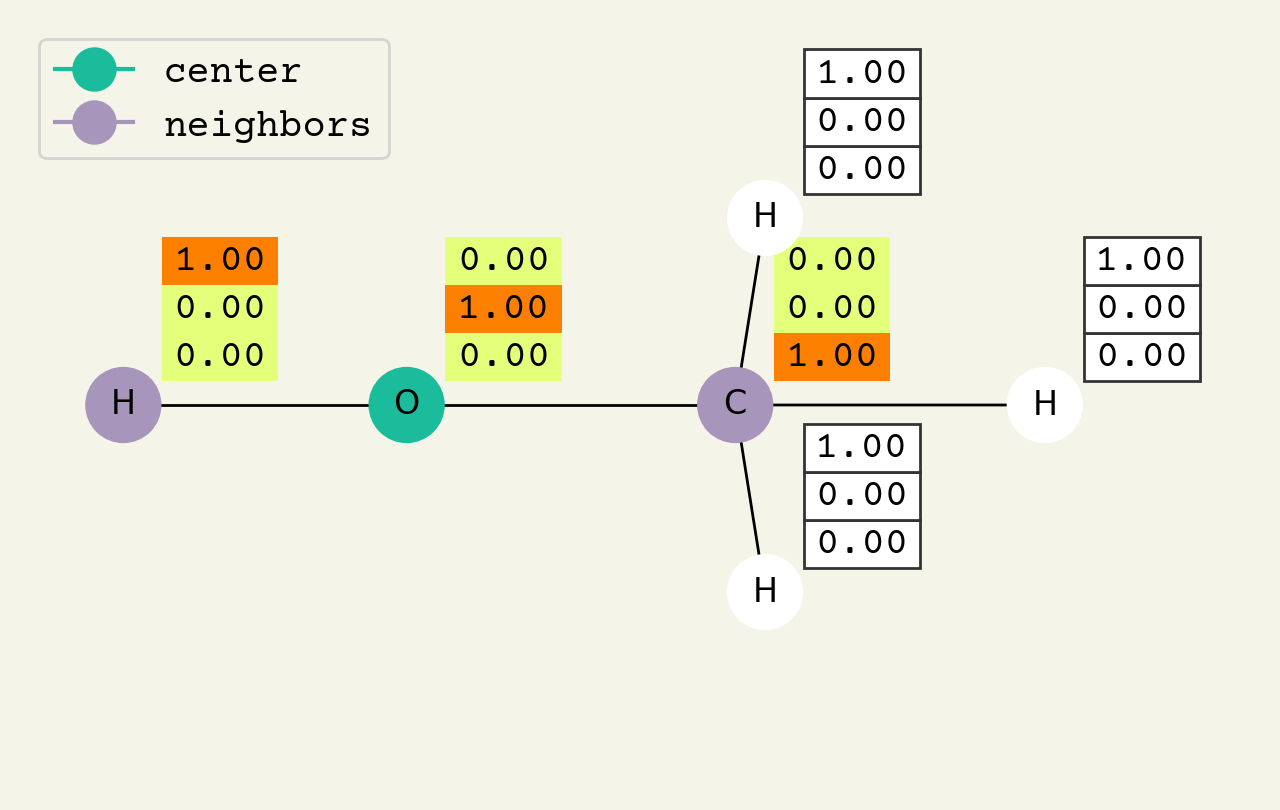
Fig. 8.2 Intermediate step of the graph convolution layer. The 3D vectors are the node features and start as one-hot, so a [1.00, 0.00, 0.00] means hydrogen. The center node will be updated by averaging its neighbors features.#
To help understand the GCN layer, look at Fig. 8.2. It shows an intermediate step of the GCN layer. Each node feature is represented here as a one-hot encoded vector at input. The animation in Fig. 8.3 shows the averaging process over neighbor features. To make this animation easy to follow, the trainable weights and activation functions are not considered. Note that the animation repeats for a second layer. Watch how the “information” about there being an oxygen atom in the molecule is propagated only after two layers to each atom. All GNNs operate with similar approaches, so try to understand how this animation works.
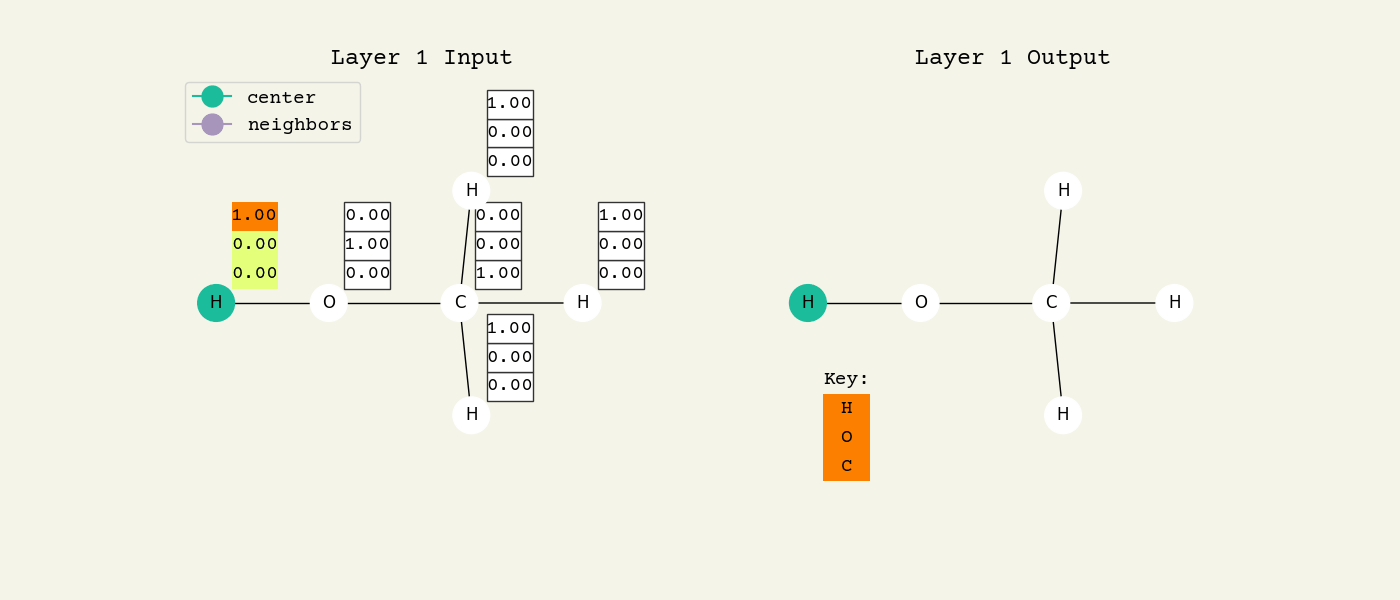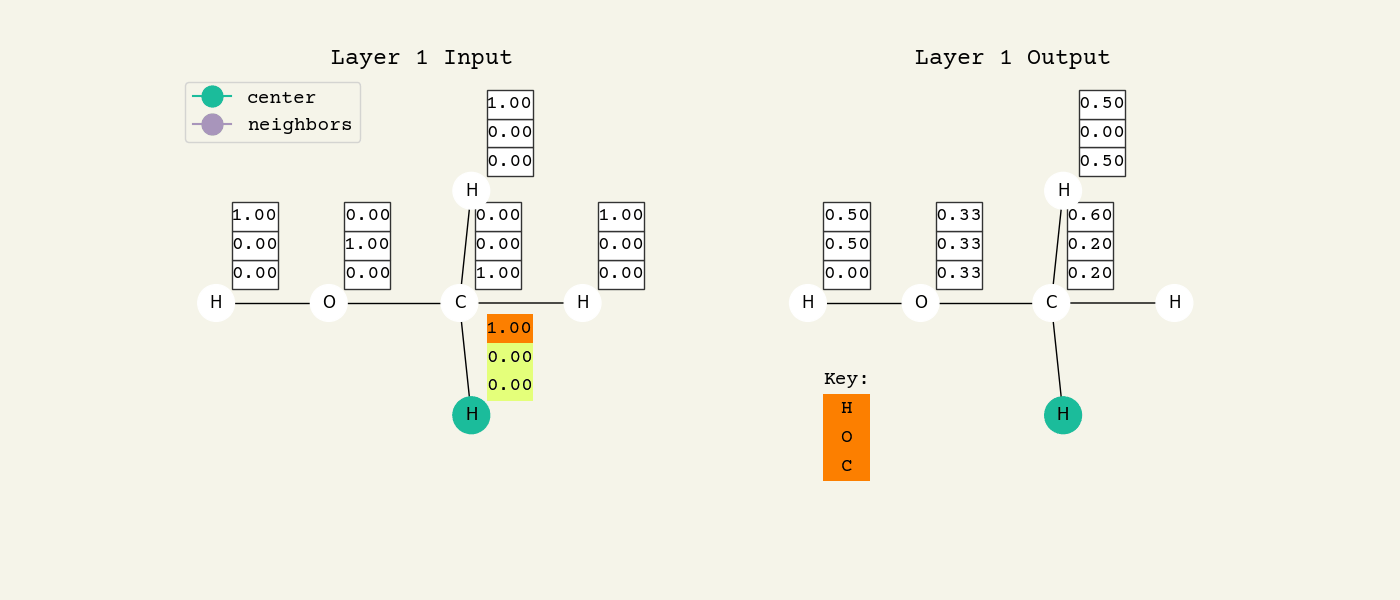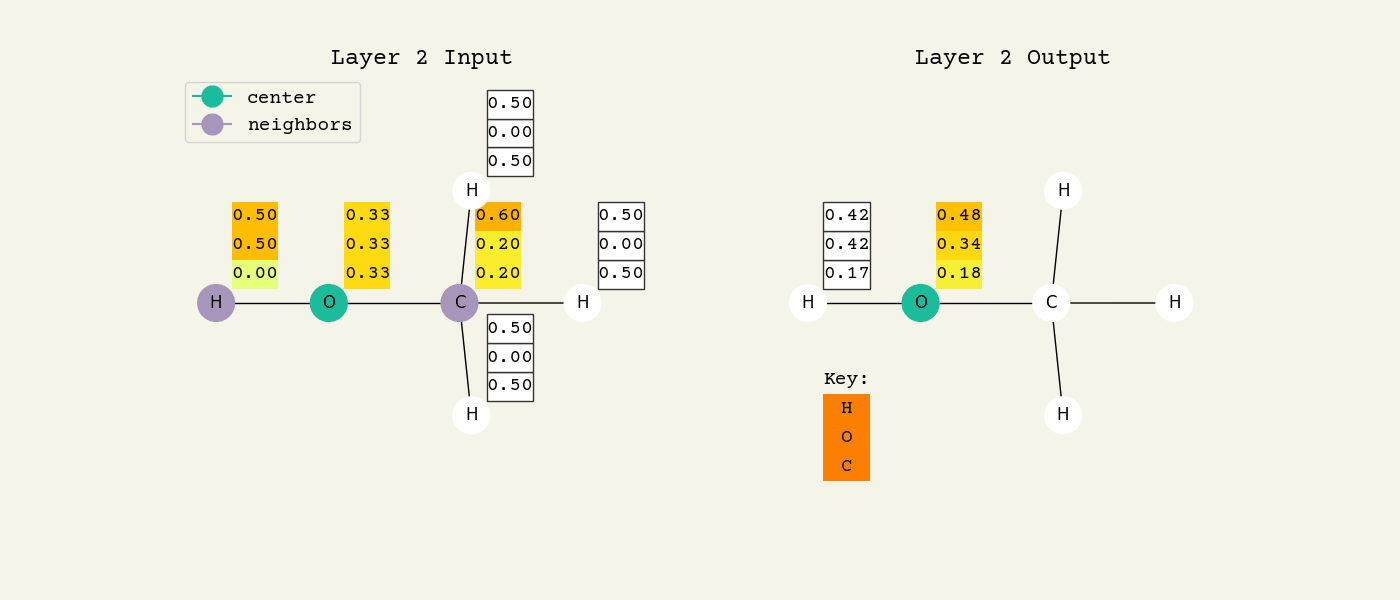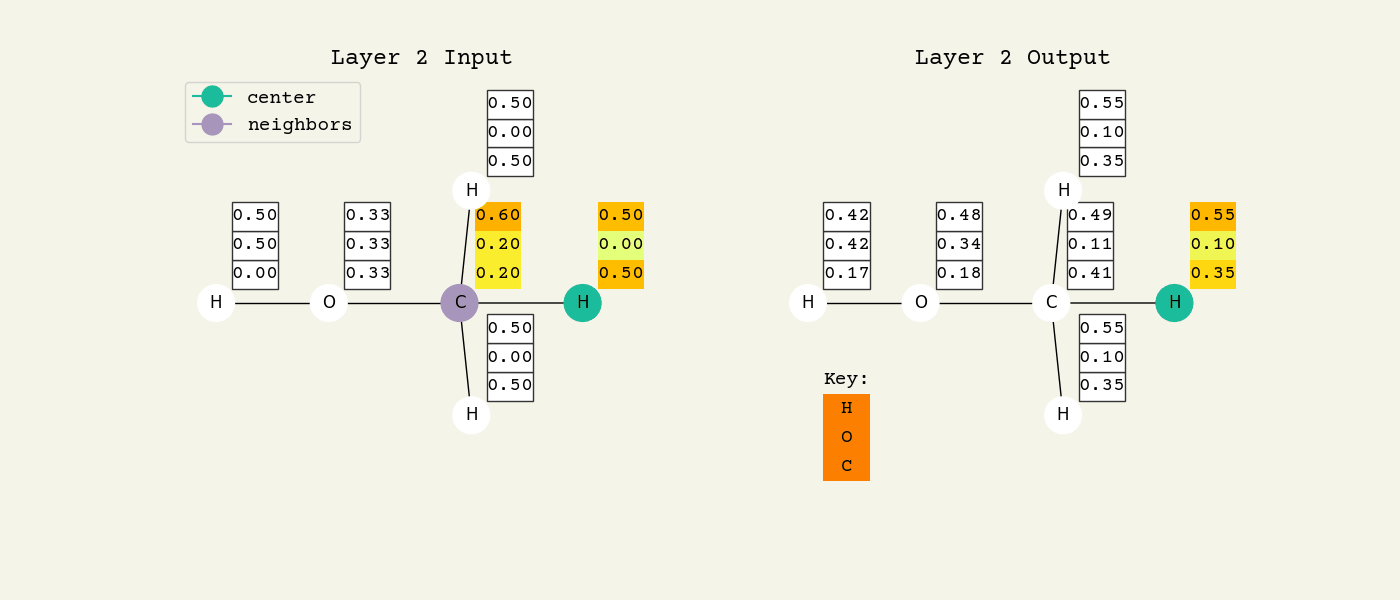
Fig. 8.3 Animation of the graph convolution layer operation. The left is input, right is output node features. Note that two layers are shown (see title change). As the animation plays out, you can see how the information about the atoms propagates through the molecule via the averaging over neigbhors. So the oxygen goes from being just an oxygen, to an oxygen bonded to C and H, to an oxygen bonded to an H and CH3. The colors just reflect the same information in the numerical values.#
8.4.1. GCN Implementation#
Let’s now create a tensor implementation of the GCN. We’ll skip the activation and trainable weights for now.
We must first compute our rank 2 adjacency matrix. The smiles2graph code above computes an adjacency tensor with feature vectors. We can fix that with a simple reduction and add the identity at the same time
nodes, adj = smiles2graph("CO")
adj_mat = np.sum(adj, axis=-1) + np.eye(adj.shape[0])
adj_mat
array([[1., 1., 1., 1., 1., 0.],
[1., 1., 0., 0., 0., 1.],
[1., 0., 1., 0., 0., 0.],
[1., 0., 0., 1., 0., 0.],
[1., 0., 0., 0., 1., 0.],
[0., 1., 0., 0., 0., 1.]])
To compute degree of each node, we can do another reduction:
degree = np.sum(adj_mat, axis=-1)
degree
array([5., 3., 2., 2., 2., 2.])
Now we can put all these pieces together into the Einstein equation
print(nodes[0])
# note to divide by degree, make the input 1 / degree
new_nodes = np.einsum("i,ij,jk->ik", 1 / degree, adj_mat, nodes)
print(new_nodes[0])
[1. 0. 0.]
[0.2 0.2 0.6]
To now implement this as a layer in Keras, we must put this code above into a new Layer subclass. The code is relatively straightforward, but you can read-up on the function names and Layer class in this tutorial. The three main changes are that we create trainable parameters self.w and use them in the tf.einsum, we use an activation self.activation, and we output both our new node features and the adjacency matrix. The reason to output the adjacency matrix is so that we can stack multiple GCN layers without having to pass the adjacency matrix each time.
class GCNLayer(tf.keras.layers.Layer):
"""Implementation of GCN as layer"""
def __init__(self, activation=None, **kwargs):
# constructor, which just calls super constructor
# and turns requested activation into a callable function
super(GCNLayer, self).__init__(**kwargs)
self.activation = tf.keras.activations.get(activation)
def build(self, input_shape):
# create trainable weights
node_shape, adj_shape = input_shape
self.w = self.add_weight(shape=(node_shape[2], node_shape[2]), name="w")
def call(self, inputs):
# split input into nodes, adj
nodes, adj = inputs
# compute degree
degree = tf.reduce_sum(adj, axis=-1)
# GCN equation
new_nodes = tf.einsum("bi,bij,bjk,kl->bil", 1 / degree, adj, nodes, self.w)
out = self.activation(new_nodes)
return out, adj
A lot of the code above is Keras/TF specific and getting the variables to the right place. There are really only two key lines here. The first is to compute the degree by summing over the columns of the adjacency matrix:
degree = tf.reduce_sum(adj, axis=-1)
The second key line is to do the GCN equation (8.3) (without the activation)
new_nodes = tf.einsum("bi,bij,bjk,kl->bil", 1 / degree, adj, nodes, self.w)
We can now try our layer:
gcnlayer = GCNLayer("relu")
# we insert a batch axis here
gcnlayer((nodes[np.newaxis, ...], adj_mat[np.newaxis, ...]))
(<tf.Tensor: shape=(1, 6, 3), dtype=float32, numpy=
array([[[0. , 0.46567526, 0.07535715],
[0. , 0.12714943, 0.05325063],
[0.01475453, 0.295794 , 0.39316285],
[0.01475453, 0.295794 , 0.39316285],
[0.01475453, 0.295794 , 0.39316285],
[0. , 0.38166213, 0. ]]], dtype=float32)>,
<tf.Tensor: shape=(1, 6, 6), dtype=float32, numpy=
array([[[1., 1., 1., 1., 1., 0.],
[1., 1., 0., 0., 0., 1.],
[1., 0., 1., 0., 0., 0.],
[1., 0., 0., 1., 0., 0.],
[1., 0., 0., 0., 1., 0.],
[0., 1., 0., 0., 0., 1.]]], dtype=float32)>)
It outputs (1) the new node features and (2) the adjacency matrix. Let’s make sure we can stack these and apply the GCN multiple times
x = (nodes[np.newaxis, ...], adj_mat[np.newaxis, ...])
for i in range(2):
x = gcnlayer(x)
print(x)
(<tf.Tensor: shape=(1, 6, 3), dtype=float32, numpy=
array([[[0. , 0.18908624, 0. ],
[0. , 0. , 0. ],
[0. , 0.145219 , 0. ],
[0. , 0.145219 , 0. ],
[0. , 0.145219 , 0. ],
[0. , 0. , 0. ]]], dtype=float32)>, <tf.Tensor: shape=(1, 6, 6), dtype=float32, numpy=
array([[[1., 1., 1., 1., 1., 0.],
[1., 1., 0., 0., 0., 1.],
[1., 0., 1., 0., 0., 0.],
[1., 0., 0., 1., 0., 0.],
[1., 0., 0., 0., 1., 0.],
[0., 1., 0., 0., 0., 1.]]], dtype=float32)>)
It works! Why do we see zeros though? Probably because we had negative numbers that were removed by our ReLU activation. This will be solved by training and increasing our dimension number.
8.5. Solubility Example#
We’ll now revisit predicting solubility with GCNs. Remember before that we used the features included with the dataset. Now we can use the molecular structures directly. Our GCN layer outputs node-level features. To predict solubility, we need to get a graph-level feature. We’ll see later how to be more sophisticated in this process, but for now let’s just take the average over all node features after our GCN layers. This is simple, permutation invariant, and gets us from node-level to graph level. Here’s an implementation of this
class GRLayer(tf.keras.layers.Layer):
"""A GNN layer that computes average over all node features"""
def __init__(self, name="GRLayer", **kwargs):
super(GRLayer, self).__init__(name=name, **kwargs)
def call(self, inputs):
nodes, adj = inputs
reduction = tf.reduce_mean(nodes, axis=1)
return reduction
The key line in that code is to just to compute the mean over the nodes (axis=1):
reduction = tf.reduce_mean(nodes, axis=1)
To complete our deep solubility predictor, we can add some dense layers and make sure we have a single-output without activation since we’re doing regression. Note this model is defined using the Keras functional API which is necessary when you have multiple inputs.
ninput = tf.keras.Input(
(
None,
100,
)
)
ainput = tf.keras.Input(
(
None,
None,
)
)
# GCN block
x = GCNLayer("relu")([ninput, ainput])
x = GCNLayer("relu")(x)
x = GCNLayer("relu")(x)
x = GCNLayer("relu")(x)
# reduce to graph features
x = GRLayer()(x)
# standard layers (the readout)
x = tf.keras.layers.Dense(16, "tanh")(x)
x = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(inputs=(ninput, ainput), outputs=x)
where does the 100 come from? Well, this dataset has lots of elements so we cannot use our size 3 one-hot encodings because we’ll have more than 3 unique elements. We previously only had C, H and O. This is a good time to update our smiles2graph function to deal with this.
def gen_smiles2graph(sml):
"""Argument for the RD2NX function should be a valid SMILES sequence
returns: the graph
"""
m = rdkit.Chem.MolFromSmiles(sml)
m = rdkit.Chem.AddHs(m)
order_string = {
rdkit.Chem.rdchem.BondType.SINGLE: 1,
rdkit.Chem.rdchem.BondType.DOUBLE: 2,
rdkit.Chem.rdchem.BondType.TRIPLE: 3,
rdkit.Chem.rdchem.BondType.AROMATIC: 4,
}
N = len(list(m.GetAtoms()))
nodes = np.zeros((N, 100))
for i in m.GetAtoms():
nodes[i.GetIdx(), i.GetAtomicNum()] = 1
adj = np.zeros((N, N))
for j in m.GetBonds():
u = min(j.GetBeginAtomIdx(), j.GetEndAtomIdx())
v = max(j.GetBeginAtomIdx(), j.GetEndAtomIdx())
order = j.GetBondType()
if order in order_string:
order = order_string[order]
else:
raise Warning("Ignoring bond order" + order)
adj[u, v] = 1
adj[v, u] = 1
adj += np.eye(N)
return nodes, adj
nodes, adj = gen_smiles2graph("CO")
model((nodes[np.newaxis], adj_mat[np.newaxis]))
<tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.0107595]], dtype=float32)>
It outputs one number! That’s always nice to have. Now we need to do some work to get a trainable dataset. Our dataset is a little bit complex because our features are tuples of tensors(\(\mathbf{V}, \mathbf{E}\)) so that our dataset is a tuple of tuples: \(\left((\mathbf{V}, \mathbf{E}), y\right)\). We use a generator, which is just a python function that can return multiple times. Our function returns once for every training example. Then we have to pass it to the from_generator tf.data.Dataset constructor which requires explicit declaration of the shapes of these examples.
def example():
for i in range(len(soldata)):
graph = gen_smiles2graph(soldata.SMILES[i])
sol = soldata.Solubility[i]
yield graph, sol
data = tf.data.Dataset.from_generator(
example,
output_types=((tf.float32, tf.float32), tf.float32),
output_shapes=(
(tf.TensorShape([None, 100]), tf.TensorShape([None, None])),
tf.TensorShape([]),
),
)
Whew, that’s a lot. Now we can do our usual splitting of the dataset.
test_data = data.take(200)
val_data = data.skip(200).take(200)
train_data = data.skip(400)
And finally, time to train.
model.compile("adam", loss="mean_squared_error")
result = model.fit(train_data.batch(1), validation_data=val_data.batch(1), epochs=10)
plt.plot(result.history["loss"], label="training")
plt.plot(result.history["val_loss"], label="validation")
plt.legend()
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
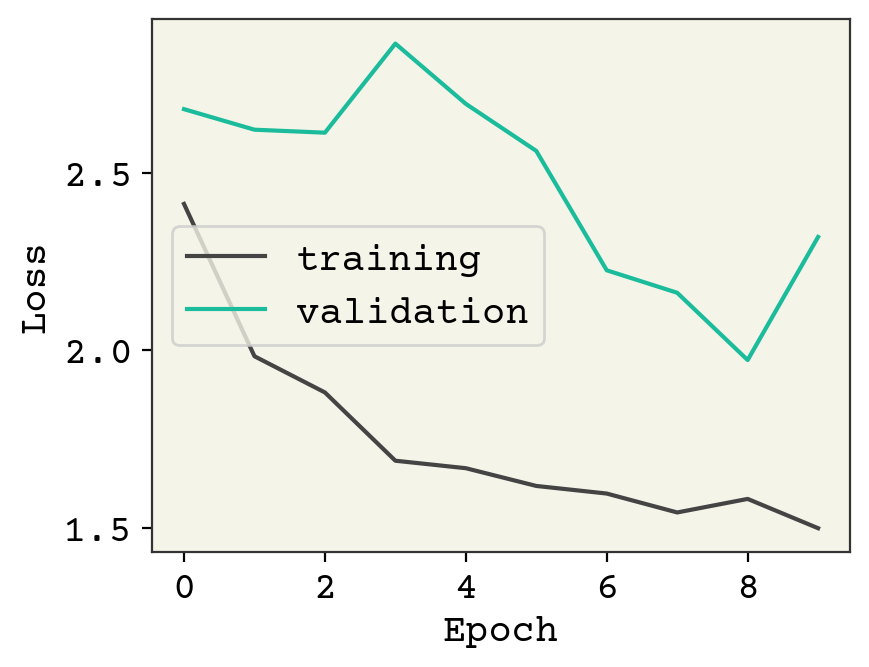
This model is definitely underfit. One reason is that our batch size is 1. This is a side-effect of making the number of atoms variable and then Keras/tensorflow has trouble batching together our data if there are two unknown dimensions. A standard trick is to group together multiple molecules into one graph, but making sure they are disconnected (no bonds between the molecules). That allows you to batch molecules without increasing the rank of your model/data.
Let’s now check the parity plot.
yhat = model.predict(test_data.batch(1), verbose=0)[:, 0]
test_y = [y for x, y in test_data]
plt.figure()
plt.plot(test_y, test_y, "-")
plt.plot(test_y, yhat, ".")
plt.text(
min(test_y) + 1,
max(test_y) - 2,
f"correlation = {np.corrcoef(test_y, yhat)[0,1]:.3f}",
)
plt.text(
min(test_y) + 1,
max(test_y) - 3,
f"loss = {np.sqrt(np.mean((test_y - yhat)**2)):.3f}",
)
plt.title("Testing Data")
plt.show()
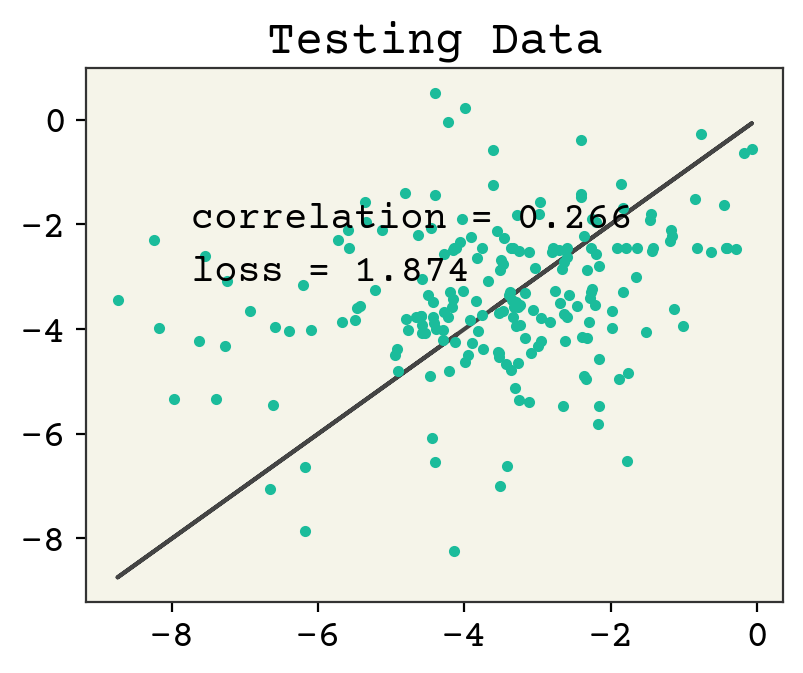
8.6. Message Passing Viewpoint#
One way to more broadly view a GCN layer is that it is a kind of “message-passing” layer. You first compute a message coming from each neighboring node:
where \(v_{{s_i}j}\) means the \(j\)th neighbor of node \(i\). The \(s_i\) means senders to \(i\). This is how a GCN computes the messages, it’s just a weight matrix times each neighbor node features. After getting the messages that will go to node \(i\), \(\vec{e}_{{s_i}j}\), we aggregate them using a function which is permutation invariant to the order of neighbors:
In the GCN this aggregation is just a mean, but it can be any permutation invariant (possibly trainable) function. Finally, we update our node using the aggregated message in the GCN:
where \(v^{'}\) indicates the new node features. This is simply the activated aggregated message. Writing it out this way, you can see how it is possible to make small changes. One important paper by Gilmer et al. explored some of these choices and described how this general idea of message passing layers does well in learning to predict molecular energies from quantum mechanics [GSR+17]. Examples of changes to the above GCN equations are to include edge information when computing the neighbor messages or use a dense neural network layer in place of \(\sigma\). You can think of the GCN as one type of a broader class of message passing graph neural networks, sometimes abbreviated as MPNN.
8.7. Gated Graph Neural Network#
One common variant of the message passing layer is the gated graph neural network (GGN) [LTBZ15]. It replaces the last equation, the node update, with
where the \(\textrm{GRU}(\cdot, \cdot)\) is a gated recurrent unit[CGCB14]. A GRU is a binary (two input arguments) neural network that is typically used in sequence modeling. The interesting property of a GGN relative to a GCN is that it has trainable parameters in the node update (from the GRU), giving the model a bit more flexibility. In a GGN, the GRU parameters are kept the same at each layer, like how a GRU is used to model sequences. What’s nice about this is that you can stack infinite GGN layers without increasing the number of trainable parameters (assuming you make \(\mathbf{W}\) the same at each layer). Thus GGNs are suited for large graphs, like a large protein or large unit cell.
8.8. Pooling#
Within the message passing viewpoint, and in general for GNNS, the way that messages from neighbors are combined is a key step. This is sometimes called pooling, since it’s similar to the pooling layer used in convolutional neural networks. Just like in pooling for convolutional neural networks, there are multiple reduction operations you can use. Typically you see a sum or mean reduction in GNNs, but you can be quite sophisticated like in the Graph Isomorphism Networks [XHLJ18]. We’ll see an example in our attention chapter of using self-attention, which can also be used for pooling. It can be tempting to focus on this step, but it’s been empirically found that the choice of pooling is not so important[LDLio19, MSK20]. The key property of the pooling is permutation invariance - we want the aggregation operation to not depend on order of nodes (or edges if pooling over them). You can find a recent review of pooling methods in Grattarola et al. [GZBA21].
You can see a more visual comparison and overview of the various pooling strategies in this distill article by Daigavane et al. [DRA21].
8.9. Readout Function#
GNNs output a graph by design. It is rare that our labels are graphs – typically we have node labels or a single graph label. An example of a node label is partial charge of atoms. An example of a graph label would be the energy of the molecule. The process of converting the graph output from the GNN into our predicted node labels or graph label is called the readout. If we have node labels, we can simply discard the edges and use our output node feature vectors from the GNN as the prediction, perhaps with a few dense layers before our predicted output label.
If we’re trying to predict a graph-level label like energy of the molecule or net charge, we need to be careful when converting from node/edge features to a graph label. If we simply put the node features into a dense layer to get to the desired shape graph label, we will lose permutation equivariance (technically it’s permutation invariance now since our output is graph label, not node labels). The readout we did above in the solubility example was a reduction over the node features to get a graph feature. Then we used this graph feature in dense layers. It turns out this is the only way [ZKR+17] to do a graph feature readout: a reduction over nodes to get graph feature and then dense layers to get predicted graph label from those graph features. You can also do some dense layers on the node features individually, but that already happens in GNN so I do not recommend it. This readout is sometimes called DeepSets because it is the same form as the DeepSets architecture, which is a permutation invariant architecture for features that are sets[ZKR+17].
You may notice that the pooling and readouts both use permutation invariant functions. Thus, DeepSets can be used for pooling and attention could be used for readouts.
8.9.1. Intensive vs Extensive#
One important consideration of a readout in regression is if your labels are intensive or extensive. An intensive label is one whose value is independent of the number of nodes (or atoms). For example, the index of refraction or solubility are intensive. The readout for an intensive label should (generally) be independent of the number of a nodes/atoms. So the reduction in the readout could be a mean or max, but not a sum. In contrast, an extensive label should (generally) use a sum for the reduction in the readout. An example of an extensive molecular property is enthalpy of formation.
8.10. Battaglia General Equations#
As you can see, message passing layers is a general way to view GNN layers. Battaglia et al. [BHB+18] went further and created a general set of equations which captures nearly all GNNs. They broke the GNN layer equations down into 3 update equations, like the node update equation we saw in the message passing layer equations, and 3 aggregation equations (6 total equations). There is a new concept in these equations: graph feature vectors. Instead of having two parts to your network (GNN then readout), a graph level feature is updated at every GNN layer. The graph feature vector is a set of features which represent the whole graph or molecule. For example, when computing solubility it may have been useful to build up a per-molecule feature vector that is eventually used to compute solubility instead of having the readout. Any kind of per-molecule quantity, like energy, should be predicted with the graph-level feature vector.
The first step in these equations is updating the edge feature vectors, written as \(\vec{e}_k\), which we haven’t seen yet:
where \(\vec{e}_k\) is the feature vector of edge \(k\), \(\vec{v}_{rk}\) is the receiving node feature vector for edge \(k\), \(\vec{v}_{sk}\) is the sending node feature vector for edge \(k\), \(\vec{u}\) is the graph feature vector, and \(\phi^e\) is one of the three update functions that the define the GNN layer. Note that these are meant to be general expressions and you define \(\phi^e\) for your specific GNN layer.
Our molecular graphs are undirected, so how do we decide which node is receiving \(\vec{v}_{rk}\) and which node is sending \(\vec{v}_{sk}\)? The individual \(\vec{e}^{'}_k\) are aggregated in the next step as all the inputs into node \(v_{rk}\). In our molecular graph, all bonds are both “inputs” and “outputs” from an atom (how else could it be?), so it makes sense to just view every bond as two directed edges: a C-H bond has an edge from C to H and an edge from H to C. In fact, our adjacency matrices already reflect that. There are two non-zero elements in them for each bond: one for C to H and one for H to C. Back to the original question, what is \(\vec{v}_{rk}\) and \(\vec{v}_{sk}\)? We consider every element in the adjacency matrix (every \(k\)) and when we’re on element \(k = \{ij\}\), which is \(A_{ij}\), then the receiving node is \(j\) and the sending node is \(i\). When we consider the companion edge \(A_{ji}\), the receiving node is \(i\) and the sending node is \(j\).
\(\vec{e}^{'}_k\) is like the message from the GCN. Except it’s more general: it can depend on the receiving node and the graph feature vector \(\vec{u}\). The metaphor of a “message” doesn’t quite apply, since a message cannot be affected by the receiver. Anyway, the new edge updates are then aggregated with the first aggregation function:
where \(\rho^{e\rightarrow v}\) is our defined function and \(E_i^{'}\) represents stacking all \(\vec{e}^{'}_k\) from edges into node i. Having our aggregated edges, we can compute the node update:
This concludes the usual steps of a GNN layer because we have new nodes and new edges. If you are updating the graph features (\(\vec{u}\)), the following additional steps may be defined:
This equation aggregates all messages/aggregated edges across the whole graph. Then we can aggregate the new nodes across the whole graph:
Finally, we can compute the update to the graph feature vector as:
8.10.1. Reformulating GCN into Battaglia equations#
Let’s see how the GCN is presented in this form. We first compute our neighbor messages for all possible neighbors using (8.8). Remember in the GCN, messages only depend on the senders.
To aggregate our messages coming into node \(i\) in (8.9), we average them.
Our node update is then the activation (8.10)
we could include the self-loop above using \(\sigma(\bar{e}^{'}_i + \vec{v}_i)\). The other functions are not used in a GCN, so those three completely define the GCN.
8.11. The SchNet Architecture#
One of the earliest and most popular GNNs is the SchNet network [SchuttSK+18]. It wasn’t really recognized at publication time as a GNN, but its now recognized as one and you’ll see it often used as a baseline model. A baseline model is a well-accepted and accurate model that is compared with.
SchNet is for atoms represented as xyz coordinates (points) – not as a molecular graph. All our previous examples used the underlying molecular graph as the input. In SchNet we will convert our xyz coodinates into a graph, so that we can apply a GNN. SchNet was developed for predicting energies and forces from atom configurations without bond information. Thus, we need to first see how a set of atoms and their positions is converted into a graph. To get the nodes, we do a similar process as above and the atomic number is passed through an embedding layer, which just means we assign a trainable vector to each atomic number (See Standard Layers for a review of embeddings).
Getting the adjacency matrix is simple too: we just make every atom be connected to every atom. It might seem confusing what the point of using a GNN is, if we’re just connecting everything. It is because GNNs are permutation equivariant. If we tried to do learning on the atoms as xyz coordinates, we would have weights depending on the ordering of atoms and probably fail to handle different numbers of atoms.
There is one more missing detail: where do the xyz coordinates go? We make the model depend on xyz coordinates by constructing the edge features from the xyz coordinates. The edge \(\vec{e}\) between atoms \(i\) and \(j\) is computed purely from their distance \(r\):
where \(\gamma\) is a hyperparameter (e.g., 10Å) and \(\mu_k\) is an equally-space grid of scalars - like [0, 5, 10, 15 , 20]. The purpose of (8.14) is similar to turning a category feature like atomic number or covalent bond type into a one-hot vector. We cannot do a one-hot vector though, because there is an infinite number of possible distances. Thus, we have a kind of “smoothing” that gives us a pseudo one-hot for distance. Let’s see an example to get a sense of it:
gamma = 1
mu = np.linspace(0, 10, 5)
def rbf(r):
return np.exp(-gamma * (r - mu) ** 2)
print("input", 2)
print("output", np.round(rbf(2), 2))
input 2
output [0.02 0.78 0. 0. 0. ]
You can see that a distance of \(r=2\) gives a vector with most of the activation for the \(k = 1\) position - which corresponds to \(\mu_1 = 2\).
We have our nodes and edges and are close to defining the GNN update equations. We need a bit more notation. I’m going to use \(h(\vec{x})\) to indicate a multilayer perceptron (MLP) – basically a 1 to 2 dense layers neural network. The exact number of dense layers and when/where activation is used in these MLPs will be defined in the implementation, because it is not so important for understanding. Recall, the definition of a dense layer is
We’ll also use a different activation function \(\sigma\) called “shifted softplus” in SchNet: \(\ln\left(0.5e^{x} + 0.5\right)\). You can see \(\sigma(x)\) compared with the usual ReLU activation in Fig. 8.4. The rationale for using shifted softplus is that it is smooth with-respect to its input, so it could be used to compute forces in a molecular dynamics simulation which requires taking smooth derivatives with respect to pairwise distances.
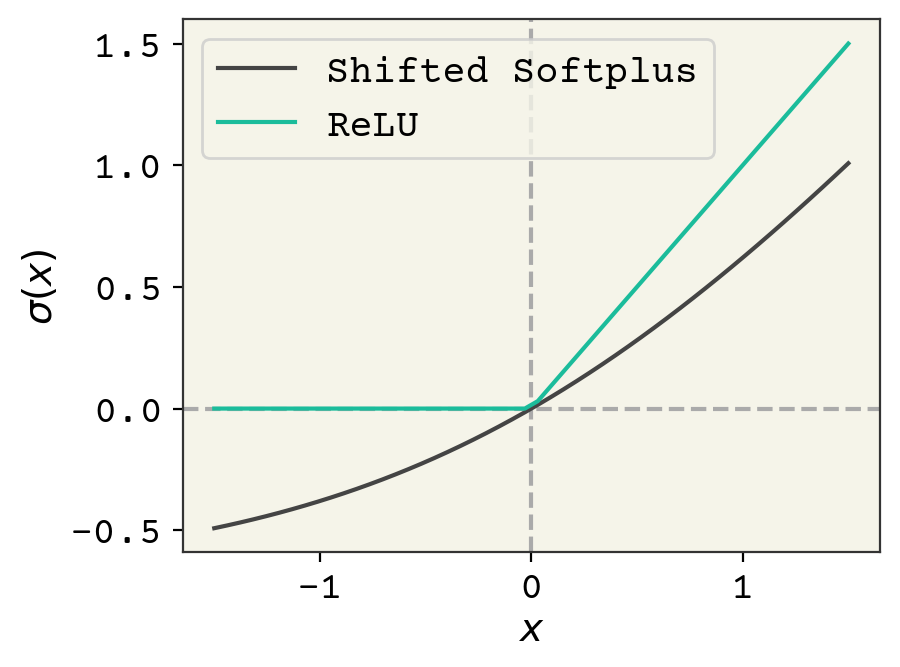
Fig. 8.4 Comparison of the usual ReLU activation function and the shifted softplus used in the SchNet model.#
Now, the GNN equations! The edge update equation (8.8) is composed of two pieces. First, we run the incoming edge feature through an MLP and the atoms through an MLP. Then the result is run through an MLP:
The next equation is the edge aggregation equation, (8.9). For SchNet, the edge aggregation is a sum over the neighbor atom features.
Finally, the node update equation for SchNet is:
The GNN updates are applied typically 3-6 times. Although we have an edge update equation, like in GCN we do not actually override the edges and keep them the same at each layer. The original SchNet was for predicting energies and forces, so a readout can be done using sum-pooling or any other strategy described above.
These are sometimes changed, but in the original SchNet paper \(h_1\) is one dense layer without activation, \(h_2\) is two dense layers with activation, and \(h_3\) is 2 dense layers with activation on the first and not the second.
What is SchNet?
The key GNN feature of a SchNet-like GNN are (1) use edge & node features in the edge update (message construction):
where \(h_i()\)s are some trainable functions and (2) use a residue in the node update:
All the other details about how to featurize the edges, how deep \(h_i\) is, what activation to choose, how to readout, and how to convert point clouds to graphs are about the specific SchNet model in [SchuttSK+18].
8.12. SchNet Example: Predicting Space Groups#
Our next example will be a SchNet model that predict space groups of points. Identifying the space group of atoms is an important part of crystal structure identification, and when doing simulations of crystallization. Our SchNet model will take as input points and output the predicted space group. This is a classification problem; specifically it is multi-class becase a set of points should only be in one space group. To simplify our plots and analysis, we will work in 2D where there are 17 possible space groups.
Our data for this is a set of points from various point groups. The features are xyz coordinates and the label is the space group. We will not have multiple atom types for this problem. The hidden cell below loads the data and reshapes it for the example.
import gzip
import pickle
import urllib
urllib.request.urlretrieve(
"https://github.com/whitead/dmol-book/raw/main/data/sym_trajs.pb.gz",
"sym_trajs.pb.gz",
)
with gzip.open("sym_trajs.pb.gz", "rb") as f:
trajs = pickle.load(f)
label_str = list(set([k.split("-")[0] for k in trajs]))
# now build dataset
def generator():
for k, v in trajs.items():
ls = k.split("-")[0]
label = label_str.index(ls)
traj = v
for i in range(traj.shape[0]):
yield traj[i], label
data = tf.data.Dataset.from_generator(
generator,
output_signature=(
tf.TensorSpec(shape=(None, 2), dtype=tf.float32),
tf.TensorSpec(shape=(), dtype=tf.int32),
),
).shuffle(
1000,
reshuffle_each_iteration=False, # do not change order each time (!) otherwise will contaminate
)
# The shuffling above is really important because this dataset is in order of labels!
val_data = data.take(100)
test_data = data.skip(100).take(100)
train_data = data.skip(200)
Let’s take a look at a few examples from the dataset
The Data
This data was generated from [CW22] and all points are constrained to match the space group exactly during a molecular dynamics simulation. The trajectories were NPT with a positive pressure and followed the procedure in that paper for Figure 2. The force field is Lennard-Jones with \(\sigma=1\) and \(\epsilon=1\)
fig, axs = plt.subplots(4, 5, figsize=(12, 8))
axs = axs.flatten()
# get a few example and plot them
for i, (x, y) in enumerate(data):
if i == 20:
break
axs[i].plot(x[:, 0], x[:, 1], ".")
axs[i].set_title(label_str[y.numpy()])
axs[i].axis("off")

You can see that there is a variable number of points and a few examples for each space group. The goal is to infer those titles on the plot from the points alone.
8.12.1. Building the graphs#
We now need to build the graphs for the points. The nodes are all identical - so they can just be 1s (we’ll reserve 0 in case we want to mask or pad at some point in the future). As described in the SchNet section above, the edges should be distance to every other atom. In most implementations of SchNet, we practically add a cut-off on either distance or maximum degree (edges per node). We’ll do maximum degree for this work of 16.
I have a function below that is a bit sophisticated. It takes a matrix of point positions in arbitrary dimension and returns the distances and indices to the nearest k neighbors - exactly what we need. It uses some tricks from Tensors and Shapes. However, it is not so important for you to understand this function. Just know it takes in points and gives us the edge features and edge nodes.
# this decorator speeds up the function by "compiling" it (tracing it)
# to run efficienty
@tf.function(
reduce_retracing=True,
)
def get_edges(positions, NN, sorted=True):
M = tf.shape(input=positions)[0]
# adjust NN
NN = tf.minimum(NN, M)
qexpand = tf.expand_dims(positions, 1) # one column
qTexpand = tf.expand_dims(positions, 0) # one row
# repeat it to make matrix of all positions
qtile = tf.tile(qexpand, [1, M, 1])
qTtile = tf.tile(qTexpand, [M, 1, 1])
# subtract them to get distance matrix
dist_mat = qTtile - qtile
# mask distance matrix to remove zros (self-interactions)
dist = tf.norm(tensor=dist_mat, axis=2)
mask = dist >= 5e-4
mask_cast = tf.cast(mask, dtype=dist.dtype)
# make masked things be really far
dist_mat_r = dist * mask_cast + (1 - mask_cast) * 1000
topk = tf.math.top_k(-dist_mat_r, k=NN, sorted=sorted)
return -topk.values, topk.indices
Let’s see how this function works by showing the connections between points in one of our examples. I’ve hidden the code below. It shows some point’s neighbors and connects them so you can get a sense of how a set of points is converted into a graph. The complete graph will have all points’ neighborhoods.
from matplotlib import collections
fig, axs = plt.subplots(2, 3, figsize=(12, 8))
axs = axs.flatten()
for i, (x, y) in enumerate(data):
if i == 6:
break
e_f, e_i = get_edges(x, 8)
# make things easier for plotting
e_i = e_i.numpy()
x = x.numpy()
y = y.numpy()
# make lines from origin to its neigbhors
lines = []
colors = []
for j in range(0, x.shape[0], 23):
# lines are [(xstart, ystart), (xend, yend)]
lines.extend([[(x[j, 0], x[j, 1]), (x[k, 0], x[k, 1])] for k in e_i[j]])
colors.extend([f"C{j}"] * len(e_i[j]))
lc = collections.LineCollection(lines, linewidths=2, colors=colors)
axs[i].add_collection(lc)
axs[i].plot(x[:, 0], x[:, 1], ".")
axs[i].axis("off")
axs[i].set_title(label_str[y])
plt.show()
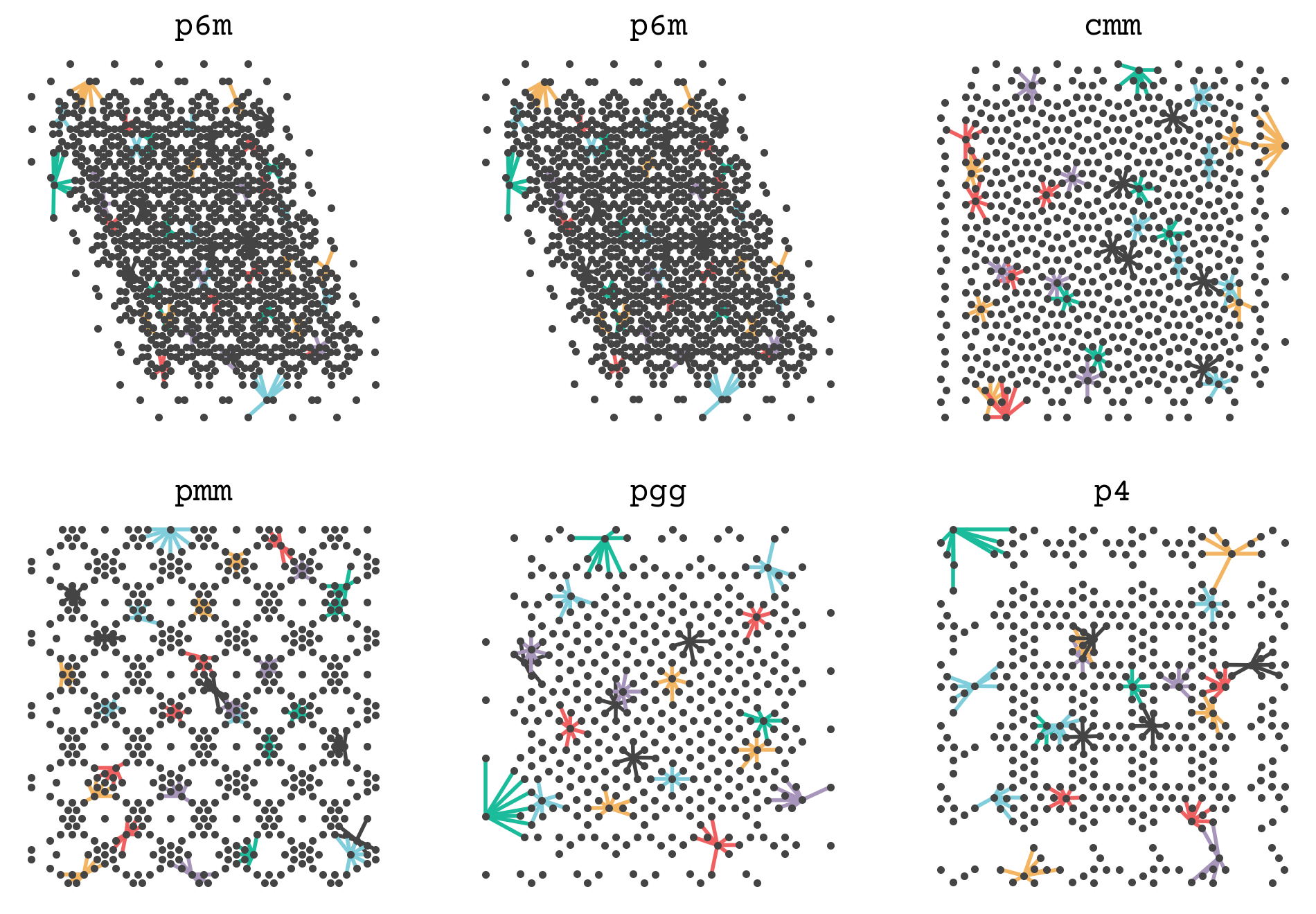
We will now add this function and the edge featurization of SchNet (8.14) to get the graphs for the GNN steps.
MAX_DEGREE = 16
EDGE_FEATURES = 8
MAX_R = 20
gamma = 1
mu = np.linspace(0, MAX_R, EDGE_FEATURES)
def rbf(r):
return tf.exp(-gamma * (r[..., tf.newaxis] - mu) ** 2)
def make_graph(x, y):
edge_r, edge_i = get_edges(x, MAX_DEGREE)
edge_features = rbf(edge_r)
return (tf.ones(tf.shape(x)[0], dtype=tf.int32), edge_features, edge_i), y[None]
graph_train_data = train_data.map(make_graph)
graph_val_data = val_data.map(make_graph)
graph_test_data = test_data.map(make_graph)
Let’s examine one graph to see what it looks like. We’ll slice out only the first nodes.
for (n, e, nn), y in graph_train_data:
print("first node:", n[1].numpy())
print("first node, first edge features:", e[1, 1].numpy())
print("first node, all neighbors", nn[1].numpy())
print("label", y.numpy())
break
first node: 1
first node, first edge features: [4.87925738e-01 1.75932534e-02 5.15009597e-11 1.22395275e-26
0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00]
first node, all neighbors [ 3 2 12 16 4 8 0 9 23 15 353 20 361 223 21 10]
label [1]
8.12.2. Implementing the MLPs#
Now we can implement the SchNet model! Let’s start with the \(h_1,h_2,h_3\) MLPs that are used in the GNN update equations. In the SchNet paper these each had different numbers of layers and different decisions about which layers had activation. Let’s create them now.
def ssp(x):
# shifted softplus activation
return tf.math.log(0.5 * tf.math.exp(x) + 0.5)
def make_h1(units):
return tf.keras.Sequential([tf.keras.layers.Dense(units)])
def make_h2(units):
return tf.keras.Sequential(
[
tf.keras.layers.Dense(units, activation=ssp),
tf.keras.layers.Dense(units, activation=ssp),
]
)
def make_h3(units):
return tf.keras.Sequential(
[tf.keras.layers.Dense(units, activation=ssp), tf.keras.layers.Dense(units)]
)
One detail that can be missed is that the weights in each MLP should change in each layer of SchNet. Thus, we’ve written the functions above to always return a new MLP. This means that a new set of trainable weights is generated on each call, meaning there is no way we could erroneously have the same weights in multiple layers.
8.12.3. Implementing the GNN#
Now we have all the pieces to make the GNN. This code will be very similar to the GCN example above, except we now have edge features. One more detail is that our readout will be an MLP as well, following the SchNet paper. The only change we’ll make is that we want our output property to be (1) multi-class classification and (2) intensive (independent of number of atoms). So we’ll end with an average (intensive) and end with an output vector of logits the size of our labels.
class SchNetModel(tf.keras.Model):
"""Implementation of SchNet Model"""
def __init__(self, gnn_blocks, channels, label_dim, **kwargs):
super(SchNetModel, self).__init__(**kwargs)
self.gnn_blocks = gnn_blocks
# build our layers
self.embedding = tf.keras.layers.Embedding(2, channels)
self.h1s = [make_h1(channels) for _ in range(self.gnn_blocks)]
self.h2s = [make_h2(channels) for _ in range(self.gnn_blocks)]
self.h3s = [make_h3(channels) for _ in range(self.gnn_blocks)]
self.readout_l1 = tf.keras.layers.Dense(channels // 2, activation=ssp)
self.readout_l2 = tf.keras.layers.Dense(label_dim)
def call(self, inputs):
nodes, edge_features, edge_i = inputs
# turn node types as index to features
nodes = self.embedding(nodes)
for i in range(self.gnn_blocks):
# get the node features per edge
v_sk = tf.gather(nodes, edge_i)
e_k = self.h1s[i](v_sk) * self.h2s[i](edge_features)
e_i = tf.reduce_sum(e_k, axis=1)
nodes += self.h3s[i](e_i)
# readout now
nodes = self.readout_l1(nodes)
nodes = self.readout_l2(nodes)
return tf.reduce_mean(nodes, axis=0)
Remember that the key attributes of a SchNet GNN are the way that we use edge and node features. We can see the mixing of these two in the key line for computing the edge update (computing message values):
e_k = self.h1s[i](v_sk) * self.h2s[i](edge_features)
followed by aggregation of the edges updates (pooling messages):
e_i = tf.reduce_sum(e_k, axis=1)
and the node update
nodes += self.h3s[i](e_i)
Also of note is how we go from node features to multi-classs. We use dense layers that get the shape per-node into the number of classes
self.readout_l1 = tf.keras.layers.Dense(channels // 2, activation=ssp)
self.readout_l2 = tf.keras.layers.Dense(label_dim)
and then we take the average over all nodes
return tf.reduce_mean(nodes, axis=0)
Let’s now use the model on some data.
small_schnet = SchNetModel(3, 32, len(label_str))
for x, y in graph_train_data:
yhat = small_schnet(x)
break
print(yhat.numpy())
[ 1.7014749e-02 1.2131847e-02 -4.6764631e-03 -1.0873002e-02
7.4983016e-03 1.2150299e-02 3.1273261e-02 1.7637234e-02
-2.1602984e-03 2.6902608e-03 -1.9115655e-02 -1.0214287e-02
1.0792590e-03 1.4398353e-05 -9.2129409e-03 2.0333942e-02
9.9622970e-03]
The output is the correct shape and remember it is logits. To get a class prediction that sums to probability 1, we need to use a softmax:
print("predicted class", tf.nn.softmax(yhat).numpy())
predicted class [0.05956277 0.05927264 0.0582847 0.05792465 0.05899863 0.05927373
0.06041813 0.05959986 0.05843153 0.05871565 0.05744916 0.05796282
0.05862113 0.05855874 0.05802089 0.0597608 0.05914419]
8.12.4. Training#
Great! It is untrained though. Now we can set-up training. Our loss will be cross-entropy from logits, but we need to be careful on the form. Our labels are integers - which is called “sparse” labels because they are not full one-hots. Mult-class classification is also known as categorical classification. Thus, the loss we want is sparse categorical cross entropy from logits.
small_schnet.compile(
optimizer=tf.keras.optimizers.Adam(1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics="sparse_categorical_accuracy",
)
result = small_schnet.fit(graph_train_data, validation_data=graph_val_data, epochs=20)
plt.plot(result.history["sparse_categorical_accuracy"], label="training accuracy")
plt.plot(result.history["val_sparse_categorical_accuracy"], label="validation accuracy")
plt.axhline(y=1 / 17, linestyle="--", label="random")
plt.legend()
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.show()
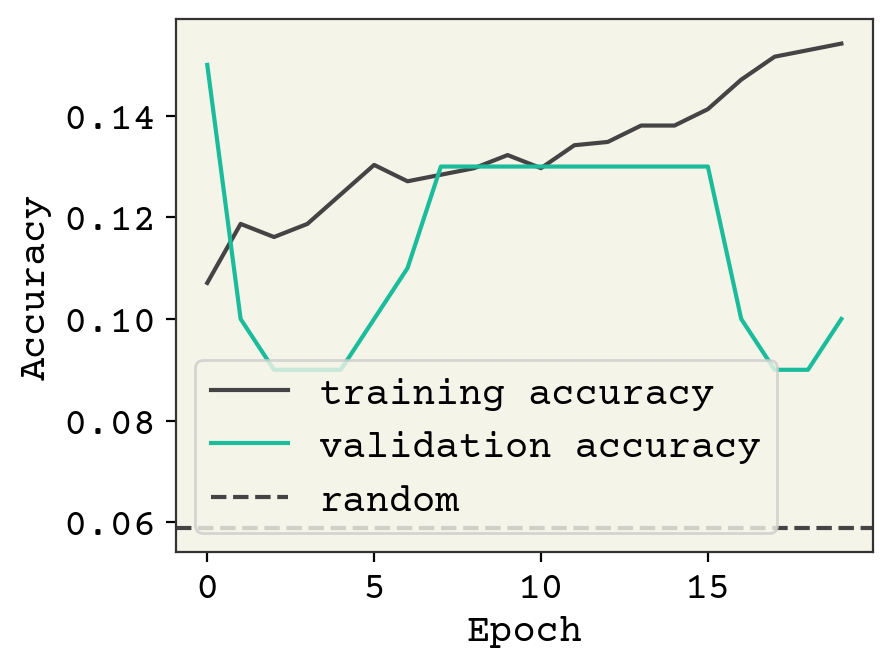
The accuracy is not great, but it looks like we could keep training. We have a very small SchNet here. Standard SchNet described in [SchuttSK+18] uses 6 layers and 64 channels and 300 edge features. We have 3 layers and 32 channels. Nevertheless, we’re able to get some learning. Let’s visually see what’s going on with the trained model on some test data
fig, axs = plt.subplots(4, 5, figsize=(12, 8))
axs = axs.flatten()
for i, ((x, y), (gx, _)) in enumerate(zip(test_data, graph_test_data)):
if i == 20:
break
axs[i].plot(x[:, 0], x[:, 1], ".")
yhat = small_schnet(gx)
yhat_i = tf.math.argmax(tf.nn.softmax(yhat)).numpy()
axs[i].set_title(f"True: {label_str[y.numpy()]}\nPredicted: {label_str[yhat_i]}")
axs[i].axis("off")
plt.tight_layout()
plt.show()
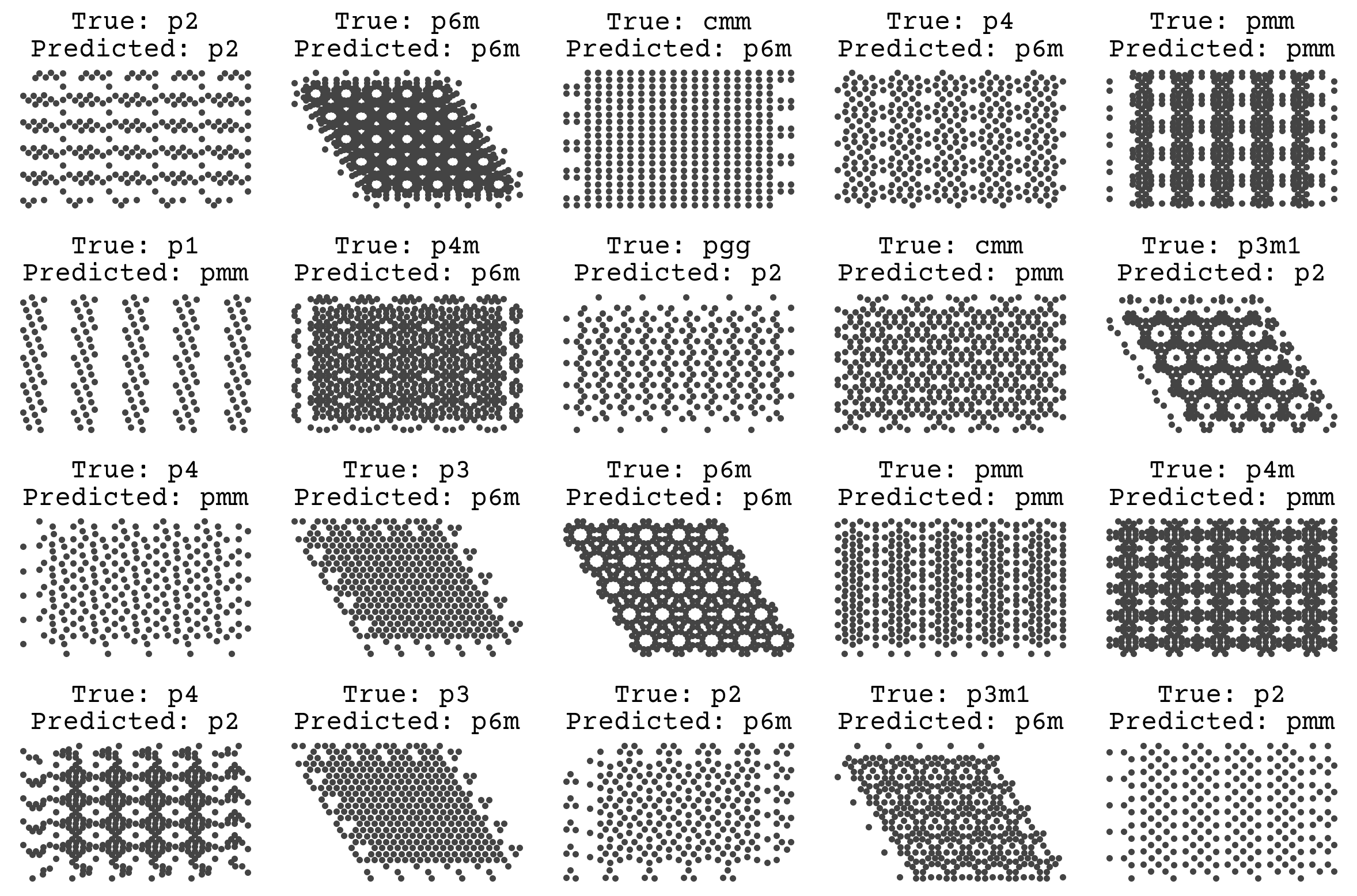
We’ll revisit this example later! One unique fact about this dataset is that it is synthetic, meaning there is no label noise. As discussed in Regression & Model Assessment, that removes the possibility of overfitting and leads us to favor high variance models. The goal of teaching a model to predict space groups is to apply it on real simulations or microscopy data, which will certainly have noise. We could have mimicked this by adding noise to the labels in the data and/or by randomly removing atoms to simulate defects. This would better help our model work in a real setting.
8.13. Current Research Directions#
8.13.1. Common Architecture Motifs and Comparisons#
We’ve now seen message passing layer GNNs, GCNs, GGNs, and the generalized Battaglia equations. You’ll find common motifs in the architectures, like gating, Attention Layers, and pooling strategies. For example, Gated GNNS (GGNs) can be combined with attention pooling to create Gated Attention GNNs (GAANs)[ZSX+18]. GraphSAGE is similar to a GCN but it samples when pooling, making the neighbor-updates of fixed dimension[HYL17]. So you’ll see the suffix “sage” when you sample over neighbors while pooling. These can all be represented in the Battaglia equations, but you should be aware of these names.
The enormous variety of architectures has led to work on identifying the “best” or most general GNN architecture [DJL+20, EPBM19, SMBGunnemann18]. Unfortunately, the question of which GNN architecture is best is as difficult as “what benchmark problems are best?” Thus there are no agreed-upon conclusions on the best architecture. However, those papers are great resources on training, hyperparameters, and reasonable starting guesses and I highly recommend reading them before designing your own GNN. There has been some theoretical work to show that simple architectures, like GCNs, cannot distinguish between certain simple graphs [XHLJ18]. How much this practically matters depends on your data. Ultimately, there is so much variety in hyperparameters, data equivariances, and training decisions that you should think carefully about how much the GNN architecture matters before exploring it with too much depth.
8.13.2. Nodes, Edges, and Features#
You’ll find that most GNNs use the node-update equation in the Battaglia equations but do not update edges. For example, the GCN will update nodes at each layer but the edges are constant. Some recent work has shown that updating edges can be important for learning when the edges have geometric information, like if the input graph is a molecule and the edges are distance between the atoms [KGrossGunnemann20]. As we’ll see in the chapter on equivariances (Input Data & Equivariances), one of the key properties of neural networks with point clouds (i.e., Cartesian xyz coordinates) is to have rotation equivariance. [KGrossGunnemann20] showed that you can achieve this if you do edge updates and encode the edge vectors using a rotation equivariant basis set with spherical harmonics and Bessel functions. These kind of edge updating GNNs can be used to predict protein structure [JES+20].
Another common variation on node features is to pack more into node features than just element identity. In many examples, you will see people inserting valence, elemental mass, electronegativity, a bit indicating if the atom is in a ring, a bit indicating if the atom is aromatic, etc. Typically these are unnecessary, since a model should be able to learn any of these features which are computed from the graph and node elements. However, we and others have empirically found that some can help, specifically indicating if an atom is in a ring [LWC+20]. Choosing extra features to include though should be at the bottom of your list of things to explore when designing and using GNNs.
8.13.3. Beyond Message Passing#
One of the common themes of GNN research is moving “beyond message passing,” where message passing is the message construction, aggregation, and node update with messages. Some view this as impossible – claiming that all GNNs can be recast as message passing [Velivckovic22]. Another direction is on disconnecting the underlying graph being input to the GNN and the graph used to compute updates. We sort of saw this above with SchNet, where we restricted the maximum degree for the message passing. More useful are ideas like “lifting” the graphs into more structured objects like simplicial complexes [BFO+21]. Finally, you can also choose where to send the messages beyond just neighbors [TZK21]. For example, all nodes on a path could communicate messages or all nodes in a clique.
8.13.4. Do we need graphs?#
It is possible to convert a graph into a string if you’re working with an adjacency matrix without continuous values. Molecules specifically can be converted into a string. This means you can use layers for sequences/strings (e.g., recurrent neural networks or 1D convolutions) and avoid the complexities of a graph neural network. SMILES is one way to convert molecular graphs into strings. With SMILES, you cannot predict a per-atom quantity and thus a graph neural network is required for atom/bond labels. However, the choice is less clear for per-molecule properties like toxicity or solubility. There is no consensus about if a graph or string/SMILES representation is better. SMILES can exceed certain graph neural networks in accuracy on some tasks. SMILES is typically better on generative tasks. Graphs obviously beat SMILES in label representations, because they have granularity of bonds/edges. We’ll see how to model SMILES in Deep Learning on Sequences, but it is an open question of which is better.
8.13.5. Stereochemistry/Chiral Molecules#
Stereochemistry is fundamentally a 3D property of molecules and thus not present in the covalent bonding. It is measured experimentally by seeing if molecules rotate polarized light and a molecule is called chiral or “optically active” if it is experimentally known to have this property. Stereochemistry is the categorization of how molecules can preferentially rotate polarized light through asymmetries with respect to their mirror images. In organic chemistry, the majority of stereochemistry is of enantiomers. Enantiomers are “handedness” around specific atoms called chiral centers which have 4 or more different bonded atoms. These may be treated in a graph by indicating which nodes are chiral centers (nodes) and what their state or mixture of states (racemic) are. This can be treated as an extra processing step. Amino acids and thus all proteins are entaniomers with only one form present. This chirality of proteins means many drug molecules can be more or less potent depending on their stereochemistry.
Fig. 8.5 This is a molecule with axial stereochemistry. Its small helix could be either left or right-handed.#
Adding node labels is not enough generally. Molecules can interconvert between stereoisomers at chiral centers through a process called tautomerization. There are also types of stereochemistry that are not at a specific atom, like rotamers that are around a bond. Then there is stereochemistry that involves multiple atoms like axial helecene. As shown in Fig. 8.5, the molecule has no chiral centers but is “optically active” (experimentally measured to be chiral) because of its helix which can be left- or right-handed.
8.14. Chapter Summary#
Molecules can be represented by graphs by using one-hot encoded feature vectors that show the elemental identity of each node (atom) and an adjacency matrix that show immediate neighbors (bonded atoms).
Graph neural networks are a category of deep neural networks that have graphs as inputs.
One of the early GNNs is the Kipf & Welling GCN. The input to the GCN is the node feature vector and the adjacency matrix, and returns the updated node feature vector. The GCN is permutation invariant because it averages over the neighbors.
A GCN can be viewed as a message-passing layer, in which we have senders and receivers. Messages are computed from neighboring nodes, which when aggregated update that node.
A gated graph neural network is a variant of the message passing layer, for which the nodes are updated according to a gated recurrent unit function.
The aggregation of messages is sometimes called pooling, for which there are multiple reduction operations.
GNNs output a graph. To get a per-atom or per-molecule property, use a readout function. The readout depends on if your property is intensive vs extensive
The Battaglia equations encompasses almost all GNNs into a set of 6 update and aggregation equations.
You can convert xyz coordinates into a graph and use a GNN like SchNet
8.15. Exercises#
Write ethanol as a graph with one-hot node features and an adjacency tensor.
The GCN as presented is supposed to be permutation invariant. Recall the key GCN equation is :
where \(i\) is receiving node, \(j\) is sending node, \(k\) is input features, and \(l\) is output features. \(v\) is node features, \(v'\) is updated node features, \(e\) is edge, \(d\) is degree, and \(w\) are trainable parameters. Determine and show if the following variations of the GCN equation are permutation invariant:
Variant 1: $\( v_{ik}' = \sigma\left(\frac{1}{d_i}e_{ij}v_{jk}w_{k}\right) \)$
Variant 2: $\( v_{ik}' = \sigma\left(\frac{1}{d_i}e_{ij}v_{jk}w_{jk}\right) \)$
Variant 3: $\( v_{il}' = \sigma\left(\frac{1}{d_i}e_{ij}v_{jk}w_{ilk}\right) \)$
With the Battaglia equations, can you have an ‘inverse’ GCN that only updates edge features but not node features? Could it learn anything?
We would like to identify a specific atom in a molecule, like a potential site of a reaction. We have training data consisting of graphs and specific nodes. Is this regression or classification? What would be an appropriate readout and what would be the correct loss?
Propose a modification to the GCN that predicts edge properties. Contrast your network with SchNet - how is it different?
What is the relationship between the number of GCN layers and maximum number of bonds which information can pass between?
How many layers would it take for a GNN to detect if a molecule has a 6-membered ring?
8.16. Relevant Videos#
8.16.1. Intro to GNNs#
8.16.2. Overview of GNN with Molecule, Compiler Examples#
8.17. Cited References#
- DJL+20(1,2)
Vijay Prakash Dwivedi, Chaitanya K Joshi, Thomas Laurent, Yoshua Bengio, and Xavier Bresson. Benchmarking graph neural networks. arXiv preprint arXiv:2003.00982, 2020.
- BBL+17
Michael M Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, and Pierre Vandergheynst. Geometric deep learning: going beyond euclidean data. IEEE Signal Processing Magazine, 34(4):18–42, 2017.
- WPC+20
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu Philip. A comprehensive survey on graph neural networks. IEEE Transactions on Neural Networks and Learning Systems, 2020.
- LWC+20(1,2)
Zhiheng Li, Geemi P Wellawatte, Maghesree Chakraborty, Heta A Gandhi, Chenliang Xu, and Andrew D White. Graph neural network based coarse-grained mapping prediction. Chemical Science, 11(35):9524–9531, 2020.
- YCW20
Ziyue Yang, Maghesree Chakraborty, and Andrew D White. Predicting chemical shifts with graph neural networks. bioRxiv, 2020.
- XFLW+19
Tian Xie, Arthur France-Lanord, Yanming Wang, Yang Shao-Horn, and Jeffrey C Grossman. Graph dynamical networks for unsupervised learning of atomic scale dynamics in materials. Nature communications, 10(1):1–9, 2019.
- SLRPW21
Benjamin Sanchez-Lengeling, Emily Reif, Adam Pearce, and Alex Wiltschko. A gentle introduction to graph neural networks. Distill, 2021. https://distill.pub/2021/gnn-intro. doi:10.23915/distill.00033.
- XG18
Tian Xie and Jeffrey C. Grossman. Crystal graph convolutional neural networks for an accurate and interpretable prediction of material properties. Phys. Rev. Lett., 120:145301, Apr 2018. URL: https://link.aps.org/doi/10.1103/PhysRevLett.120.145301, doi:10.1103/PhysRevLett.120.145301.
- KW16
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
- GSR+17
Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. arXiv preprint arXiv:1704.01212, 2017.
- LTBZ15
Yujia Li, Daniel Tarlow, Marc Brockschmidt, and Richard Zemel. Gated graph sequence neural networks. arXiv preprint arXiv:1511.05493, 2015.
- CGCB14
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555, 2014.
- XHLJ18(1,2)
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In International Conference on Learning Representations. 2018.
- LDLio19
Enxhell Luzhnica, Ben Day, and Pietro Liò. On graph classification networks, datasets and baselines. arXiv preprint arXiv:1905.04682, 2019.
- MSK20
Diego Mesquita, Amauri Souza, and Samuel Kaski. Rethinking pooling in graph neural networks. Advances in Neural Information Processing Systems, 2020.
- GZBA21
Daniele Grattarola, Daniele Zambon, Filippo Maria Bianchi, and Cesare Alippi. Understanding pooling in graph neural networks. arXiv preprint arXiv:2110.05292, 2021.
- DRA21
Ameya Daigavane, Balaraman Ravindran, and Gaurav Aggarwal. Understanding convolutions on graphs. Distill, 2021. https://distill.pub/2021/understanding-gnns. doi:10.23915/distill.00032.
- ZKR+17(1,2)
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Russ R Salakhutdinov, and Alexander J Smola. Deep sets. In Advances in neural information processing systems, 3391–3401. 2017.
- BHB+18
Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, and others. Relational inductive biases, deep learning, and graph networks. arXiv preprint arXiv:1806.01261, 2018.
- SchuttSK+18(1,2,3)
Kristof T Schütt, Huziel E Sauceda, P-J Kindermans, Alexandre Tkatchenko, and K-R Müller. Schnet–a deep learning architecture for molecules and materials. The Journal of Chemical Physics, 148(24):241722, 2018.
- CW22
Sam Cox and Andrew D White. Symmetric molecular dynamics. arXiv preprint arXiv:2204.01114, 2022.
- ZSX+18
Jiani Zhang, Xingjian Shi, Junyuan Xie, Hao Ma, Irwin King, and Dit-Yan Yeung. Gaan: gated attention networks for learning on large and spatiotemporal graphs. arXiv preprint arXiv:1803.07294, 2018.
- HYL17
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In Advances in neural information processing systems, 1024–1034. 2017.
- EPBM19
Federico Errica, Marco Podda, Davide Bacciu, and Alessio Micheli. A fair comparison of graph neural networks for graph classification. In International Conference on Learning Representations. 2019.
- SMBGunnemann18
Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. Pitfalls of graph neural network evaluation. arXiv preprint arXiv:1811.05868, 2018.
- KGrossGunnemann20(1,2)
Johannes Klicpera, Janek Groß, and Stephan Günnemann. Directional message passing for molecular graphs. In International Conference on Learning Representations. 2020.
- JES+20
Bowen Jing, Stephan Eismann, Patricia Suriana, Raphael JL Townshend, and Ron Dror. Learning from protein structure with geometric vector perceptrons. arXiv preprint arXiv:2009.01411, 2020.
- Velivckovic22
Petar Veličković. Message passing all the way up. arXiv preprint arXiv:2202.11097, 2022.
- BFO+21
Cristian Bodnar, Fabrizio Frasca, Nina Otter, Yuguang Wang, Pietro Lio, Guido F Montufar, and Michael Bronstein. Weisfeiler and lehman go cellular: cw networks. Advances in Neural Information Processing Systems, 34:2625–2640, 2021.
- TZK21
Erik Thiede, Wenda Zhou, and Risi Kondor. Autobahn: automorphism-based graph neural nets. Advances in Neural Information Processing Systems, 2021.